
1. Overview
Decision Tree Analysis is a general, predictive modelling tool with applications spanning several different areas. In general, decision trees are constructed via an algorithmic approach that identifies ways to split a data set based on various conditions. It is one of the most widely used and practical methods for supervised learning. Decision Trees are a non-parametric supervised learning method used for both classification and regression tasks. The goal is to create a model that predicts the value of a target variable by learning simple decision rules inferred from the data features.
The decision rules are generally in the form of if-then-else statements. The deeper the tree, the more complex the rules and fitter the model.
Before we dive deep, let’s get familiar with some of the terminologies:
- Instances: Refer to the vector of features or attributes that define the input space
- Attribute: A quantity describing an instance
- Concept: The function that maps input to output
- Target Concept: The function that we are trying to find, i.e., the actual answer
- Hypothesis Class: Set of all the possible functions
- Sample: A set of inputs paired with a label, which is the correct output (also known as the Training Set)
- Candidate Concept: A concept which we think is the target concept
- Testing Set: Similar to the training set and is used to test the candidate concept and determine its performance
2. Introduction
Decision trees are simple to implement and equally easy to interpret. And decision trees are ideal for machine learning newcomers as well! Decision trees can be applied to both regression and classification problems. But the questions you should ask (and should know the answer to) are:
- what is a Decision Tree?
- How does it work?
- Why we have to use Decision Trees?
- What is the mathematics behind this algorithm?
If you are unsure about even one of these questions, you’ve come to the right place! Decision Tree is a robust machine learning algorithm that also serves as the building block for other widely used and complicated machine learning algorithms like Random Forest, XGBoost, AdaBoost and LightGBM. You can imagine why it’s essential to learn about this topic!
Modern-day programming libraries have made using any machine learning algorithm easy, but this comes at the cost of hidden implementation, a must-know for fully understanding an algorithm.
3. Terminologies
Let’s look at the basic terminology used with Decision trees:
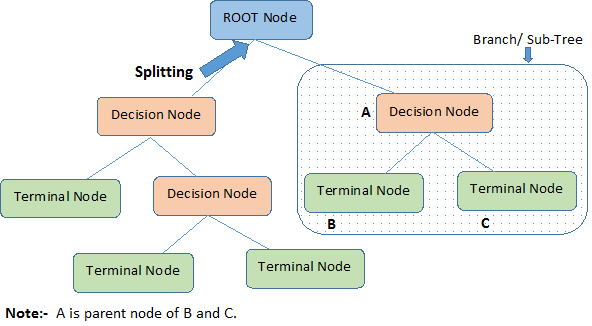
- Root Node: It represents the entire population or sample, and this further gets divided into two or more homogeneous sets.
- Leaf/ Terminal Node: Nodes do not split is called Leaf or Terminal node.
- Decision Node: When a sub-node splits into further sub-nodes, then it is called a decision node.
- Branch / Sub-Tree: A subsection of the entire tree is called a branch or sub-tree.
- Parent and Child Node: A node, which is divided into sub-nodes, is called the parent node of sub-nodes, whereas sub-nodes are the child of the parent node.
- Splitting: It is a process of dividing a node into two or more sub-nodes.
- Pruning: Pruning is when we selectively remove branches from a tree. The goal is to remove unwanted branches, improve the tree’s structure, and direct new, healthy growth.
4. What is a Decision Tree Algorithm?
A Decision Tree is a tree-like graph with nodes representing the place where we pick an attribute and ask a question; edges represent the answers to the question, and the leaves represent the actual output or class label. They are used in non-linear decision making with a simple linear decision surface.
The Decision Tree algorithm belongs to the family of supervised learning algorithms. Unlike other supervised learning algorithms, the decision tree algorithm can solve regression and classification problems.
The goal of using a Decision Tree is to create a training model that can use to predict the class or value of the target variable by learning simple decision rules inferred from prior data(training data).
In Decision Trees, we start from the tree’s root for predicting a class label for a record. We compare the values of the root attribute with the record’s attribute. Based on the comparison, we follow the branch corresponding to that value and jump to the next node.
5. Why we have to use Decision Tree Algorithm?
Decision Tree is considered one of the most useful Machine Learning algorithms since it can solve various problems. Here are a few reasons why you should use the Decision Tree:
- It is considered to be the most understandable Machine Learning algorithm, and it can be easily interpreted.
- It can be used for classification and regression problems.
- Unlike most Machine Learning algorithms, it works effectively with non-linear data.
- Constructing a Decision Tree is a speedy process since it uses only one feature per node to split the data.
- Decision Trees model data as a “Tree” of hierarchical branches. They make branches until they reach “Leaves” that represent predictions. Due to their branching structure, Decision Trees can easily model non-linear relationships.
6. How does the Decision Tree Algorithm work?
In a decision tree, for predicting the class of the given dataset, the algorithm starts from the root node of the tree. This algorithm compares the values of the root attribute with the record (real dataset) attribute and, based on the comparison, follows the branch and jumps to the next node.
For the next node, the algorithm again compares the attribute value with the other sub-nodes and move further. It continues the process until it reaches the leaf node of the tree. The complete algorithm can be better divided into the following steps:
- Step-1: Begin the tree with the root node, says S, which contains the complete dataset.
- Step-2: Find the best attribute in the dataset using Attribute Selection Measure (ASM).
- Step-3: Divide the S into subsets that contains possible values for the best attributes.
- Step-4: Generate the decision tree node, which contains the best attribute.
- Step-5: Recursively make new decision trees using the subsets of the dataset created in step -3. Continue this process until a stage is reached where you cannot further classify the nodes and called the final node as a leaf node.
Let’s take an example:
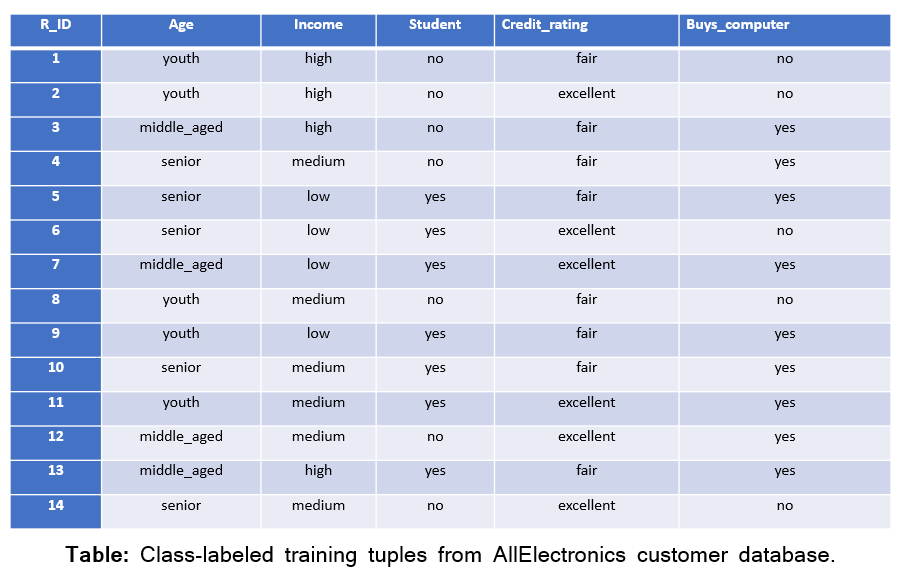
Consider the following dataset.
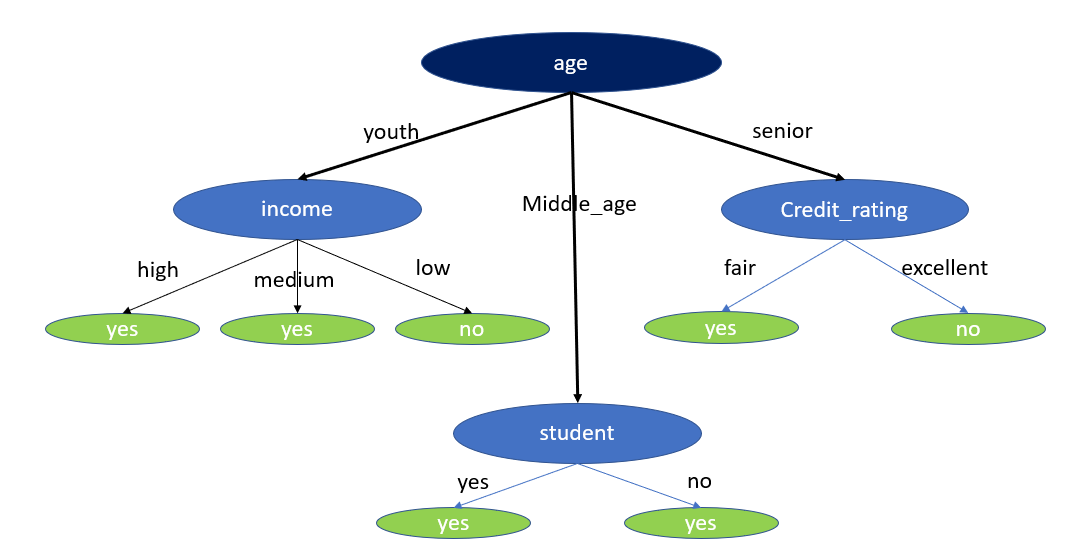
The tree for this dataset may look like this-
We will use the Attribute Selection Measure at each node to split the dataset to find the best tree.
7. Attribute Selection Measures
- Information Gain
- Information gain is used as an attribute selection measure
- Pick the attribute that has the highest Information Gain
Or
Here: D: A given data partition
A: Attribute
v: Suppose we partitioned the tuples in D on some attribute A having v distinct values, D is split into v partition or subsets, {D1, D2, … Dj}, where Dj contains those tuples in D that have outcome aj of A.
- Entropy
- Entropy is a measure of the uncertainty associated with a random variable.
- As uncertainty and or randomness increases for a result set, so does the Entropy.
- Values range from 0 – 1 to represent the Entropy of information.
Where pi is the probability that a target feature takes.
For example:
Considering the above table
Entropy(D) = Entropy(Buys_computer)
= -(9/14*log2(9/14) + 5/14*log2(5/14))
= 0.940
= Entropy(D) – (5/14)*Entropy(Syouth) – (4/14)*Entropy(Smiddle_aged) – (5/14)*Entropy(Ssenior)
= 0.940 – (5/14)*(0.347) – (4/14)*(0.0) – (5/14)*(0.347)
= 0.246
Similarily,
Gain(income, D) = 0.029
Gain(student, D) = 0.151
Gain(credit_rating, D)= 0.048
- Gini Index
- Gini index is a measure of impurity or purity used while creating a decision tree in the CART(Classification and Regression Tree) algorithm.
- An attribute with a low Gini index should be preferred as compared to the high Gini index.
- Gini index can be calculated using the below formula:
Let’s calculate the Gini Index for the credit_rating in the previous example:
P(credit_rating = fair) = 8/14
P(credit_rating = excellent) = 6/14
P(credit_rating = fair & Buys_computer = yes) = 6/8
P(credit_rating = fair & Buys_computer = no) = 2/8
P(credit_rating = excellent & Buys_computer = yes) = 3/6
P(credit_rating = excellent & Buys_computer = no) = 3/6
Gini = 1 – ((6/8)2 + (2/8)2) = 0.375
Gini = 1 – ((3/6)2 + (3/6)2) = 0.50
Weighted Gini(credit_rating) = (8/14)*(0.375) + (6/14)*(0.50)
= 0.428
Similarily, it can be calculated for others.
8. Building a Tree
To build a tree for the above example, we will start taking the tree considering the whole dataset as a root node to find whether someone buys a computer.
Now, we will find the best attribute to split using the Attribute Selection Measure(ASM). Here we are using the ID3 algorithm to build the tree. So we are going to calculate Information Gain using Entropy, which is already calculated in the ASM section.
Information Gain for the age attribute is highest, so we will split the dataset according to the age at the root node.
After the splitting at root node tree will look like this,
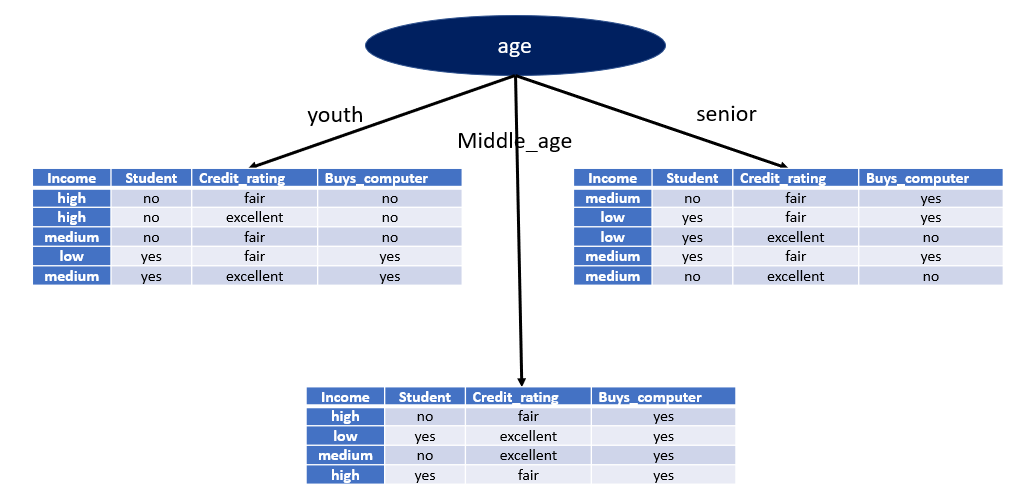
Recursively we will split all generated nodes till we reach the node where splitting is not possible.
And in this way, we will generate our required tree.
9. Advantages and Disadvantages of Decision Tree
- Advantages
- Trees are very easy to explain to people. They are even easier to explain than linear regression!
- Decision trees more closely mirror human decision-making than make the regression and classification approaches.
- Trees can be displayed graphically and easily interpreted even by a non-expert (especially small trees).
- Trees can easily handle qualitative predictors without the need to create dummy variables.
- The decision tree is considered to be a non-parametric method. This means that decision trees have no assumptions about the spatial distribution and the classifier structure.
- It can handle both numerical and categorical variables.
- Unfortunately, trees generally do not have the same level of predictive accuracy as some of the other regression and classification approaches.
- Additionally, trees can be very non-robust. In other words, a slight change in the data can cause a significant difference in the final estimated tree.
- Disadvantages
However, by aggregating many decision trees, using methods like bagging, random forests, and boosting, the predictive performance of trees can be substantially improved.
10. Practical Applications
- which product will be more profitable at launch in companies. Given the sales attributes such as market conditions, competition, price, availability of raw materials, demand, etc., a Decision Tree classifier can be used to determine which of the products would maximize the profits accurately.
- Sentiment Analysis: Sentiment Analysis is the determination of the overall opinion of a given piece of text and is predominantly used to determine if the writer’s comment towards a given product/service is positive, neutral or negative. Decision trees are very versatile classifiers and are used for sentiment analysis in many Natural Language Processing (NLP) applications.
- Energy Consumption: It is very important for electricity supply boards to correctly predict the amount of energy consumption in the near future for a particular region. This ensures that un-used power can be diverted towards an area with a higher demand to keep a regular and uninterrupted supply of energy throughout the grid. Decision Trees are often used to determine which region is expected to require more or less power in the upcoming time frame.
- Fault Diagnosis: In the Engineering domain, one of the widely used applications of decision trees is the determination of faults. In the case of load-bearing rotatory machines, it is important to determine which of the component(s) have failed and which ones can directly or indirectly be affected by the failure. This is determined by a set of measurements that are taken. Unfortunately, there are numerous measurements to take, and among them, some measures are not relevant to the detection of the fault. A Decision Tree classifier can be used to quickly determine which of these measurements are applicable in the determination of the fault.
- Select a flight to travel: Decision trees are very good at classification and hence can be used to select which flight would yield the best “bang-for-the-buck”. There are many parameters to consider, such as if the flight is connecting or non-stop, or how reliable is the service record of the given airliner, etc.
11. Trees v/s Linear Models
Regression and classification trees have a very different flavour from the more classical approaches for regression and classification. In particular, linear regression assumes a model of the form:-
whereas regression trees assume a model of the form:-
Where R1, . . ., RM represent a partition of feature space, as in Figure

Top Left: A partition of two-dimensional feature space that could not result from recursive binary splitting. Top Right: The output of recursive binary splitting on a two-dimensional example. Bottom Left: A tree corresponding to the partition in the top right panel. Bottom Right: A perspective plot of the prediction surface corresponding to that tree.
Which model is better? It depends on the problem at hand. If a linear model well approximates the relationship between the features and the response, then an approach such as linear regression will likely work well and will outperform a method such as a regression tree that does not exploit this linear structure. If there is a highly non-linear and complex relationship between the features and the response, then decision trees may outperform classical approaches. An illustrative example is displayed in Figure.

Top Row: A two-dimensional classification example in which the actual decision boundary is linear and is indicated by the shaded regions. A classical approach that assumes a linear boundary (left) will outperform a decision tree that performs splits parallel to the axes (right). Bottom Row: Here, the true decision boundary is non-linear. Here a linear model is unable to capture the true decision boundary (left), whereas a decision tree is successful (right).
The relative performances of tree-based and classical approaches can be assessed by estimating the test error, using either cross-validation or the validation set approach.
Of course, other considerations beyond simply test error may come into play in selecting a statistical learning method; for instance, in specific settings, prediction using a tree may be preferred for the sake of interpretability and visualization.




