
1. Overview
Random forest is a machine learning approach that utilizes many individual decision trees. In the tree-building process, the optimal split for each node is identified from a set of randomly chosen candidate variables. Besides their application to predict the outcome in classification and regression analyses, Random Forest can also be applied to select essential variables and groups and enable a deeper understanding of variable relations.
The Random Forests classifier belongs to the broader field of ensemble learning (methods that provide and generate several classifiers and aggregate their results). The two best-known ways are boosting and bagging classification trees. The critical point of the boosting technique is that consecutive trees add extra weight to the points incorrectly predicted by previous predictors. Upon completion, a weighted vote is used for prediction. On the contrary, for bagging (bootstrap aggregating), subsequent trees do not depend on previous trees, and each one is independently constructed using a bootstrap sample of the data set. Finally, for the prediction, a simple majority vote is utilized.
2. Introduction
In the field of data analytics, every algorithm has a price. But if we consider the overall scenario, then a maximum of the business problem has a classification task. It becomes pretty difficult to intuitively know what to adopt considering the nature of the data. But today, we will be discussing one of the top classifier techniques, which is the most trusted by data experts, and that is Random Forest Classifier. Random Forest also has a regression algorithm technique.
The word ‘Forest’ in the term suggests that it will contain many trees. The algorithm comprises a bundle of decision trees to make a classification, and it is also considered a saving technique when it comes to overfitting a decision tree model. A decision tree model has high variance and low bias, giving us a pretty unbalanced output, unlike the commonly adopted logistic regression, which has high bias and low variance. That is the only point when Random Forest comes to the rescue.
3. What is Random Forest?
Random forest algorithm is a supervised classification and regression algorithm. As the name suggests, this algorithm randomly creates a forest with several trees.
Generally, the more trees in the forest, the forest looks more robust. Similarly, in the random forest classifier, the higher the number of trees in the forest, the greater is the accuracy of the results.

In simple words, Random forest builds multiple decision trees (called the forest) and glues them together to get a more accurate and stable prediction. The forest it creates is a collection of Decision Trees trained with the bagging method.
Before we discuss Random Forest in-depth, we need to understand how Decision Trees work.
Many of you have this question in mind. Before going forward, I suggest you, please go through this article to know the basics and mathematics behind the Decision Tree.
4. Difference Between Random Forest And Decision Tree
Let’s say that you’re looking to buy a house, but you’re unable to decide which one to buy. So, you consult a few agents, and they give you a list of parameters that you should consider before buying a house. The list includes:
- Price of the house
- Locality
- Number of bedrooms
- Parking space
- Available facilities
These parameters are known as predictor variables, which are used to find the response variable. Here’s a diagrammatic illustration of how you can represent the above problem statement using a decision tree.

An important point to note here is that Decision trees are built on the entire data set by using all the predictor variables.
Now let’s see how Random Forest would solve the same problem.
Like I mentioned earlier, a Random Forest is an ensemble of decision trees. It randomly selects a set of parameters and creates a decision tree for each set of chosen parameters.
Take a look at the below figure.

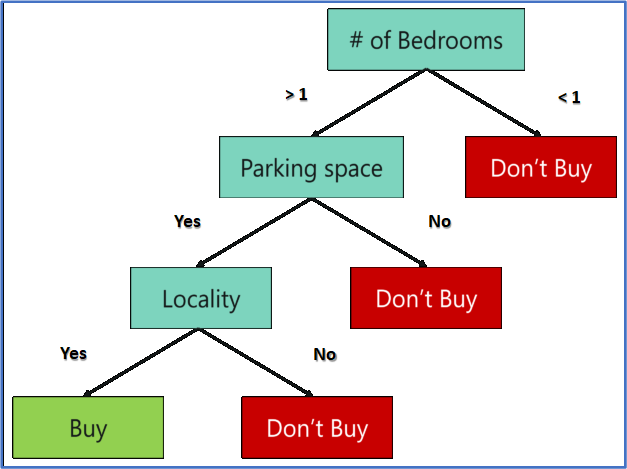
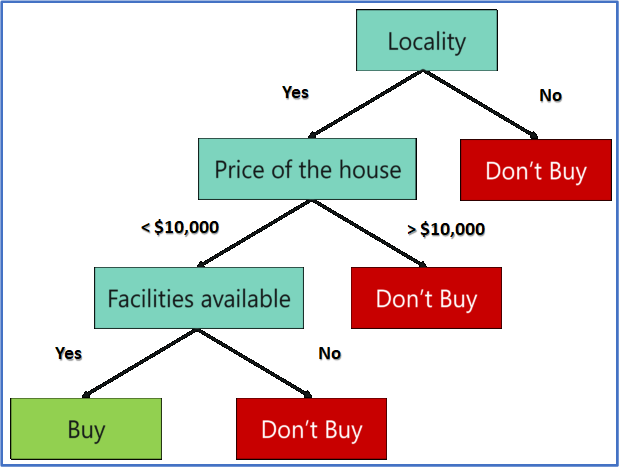
Here, I’ve created 3 Decision Trees, and each Decision Tree is taking only three parameters from the entire data set. Each decision tree predicts the outcome based on the respective predictor variables used in that tree and finally takes the average of the results from all the decision trees in the random forest.
In simple words, after creating multiple Decision trees using this method, each tree selects or votes the class (in this case, the decision trees will choose whether or not a house is bought). And the class receiving the most votes by a simple majority is termed as the predicted class.
To conclude, Decision trees are built on the entire data set using all the predictor variables. In contrast, Random Forests are used to create multiple decision trees, such that each decision tree is built only on the part of the data set.
I hope the difference between Decision Trees and Random Forest is clear.
5. Why use a Random Forest algorithm?
You might be wondering why we use Random Forest when we can solve the same problems using Decision trees. Let me explain.
- Even though Decision trees are convenient and easily implemented, they lack accuracy. Decision trees work very effectively with the training data used to build them, but they’re not flexible when classifying the new sample. It means that the accuracy during the testing phase is very low. It happens due to a process called Over-fitting.
“Over-fitting occurs when a model studies the training data to such an extent that it negatively influences the model’s performance on new data.”
- It means that the disturbance in the training data is recorded and learned as concepts by the model. But the problem here is that these concepts do not apply to the testing data and negatively impact the model’s ability to classify the new data, hence reducing the accuracy of the testing data.
It is where Random Forest comes in. It is based on the idea of bagging, which is used to reduce the variation in the predictions by combining the result of multiple Decision trees on different samples of the data set.
Now let’s focus on Random Forest.
6. Assumptions for Random Forest algorithm
Since the random forest combines multiple trees to predict the dataset class, some decision trees may predict the correct output while others may not. But together, all the trees predict the correct output. Therefore, below are two assumptions for a better Random forest classifier:
- There should be some actual values in the feature variable of the dataset so that the classifier can predict accurate results rather than a guessed result.
- The predictions from each tree must have very low correlations.
7. How does Random Forest Algorithm work?
In the random forest, we grow multiple trees in a model. To classify a new object, based on new attributes, each tree gives a classification, and we say that tree votes for that class. The forest chooses the classifications having the most votes of all the other trees in the forest-based on the importance score and takes the average difference from the output of different trees. In general, RF built multiple trees and combined them together to get a more accurate result.
Random Forest works in two-phase first is to create the random forest by combining the N decision tree, and the second is to make predictions for each tree created in the first phase.
The Working process can be explained as in the below steps:
Step-1: Select a bootstrapped dataset from the training set.
Step-2: Build the decision trees associated with the selected data points (Subsets).
- Randomly select m features from total p features.
- Among the m features, calculate the node d using the best split point.
- Split the node into daughter nodes using the best split.
- Repeat step I to III until a whole Decision Tree is not formed.
Step-3: Repeat Step 1 & 2 for N no. of times to build N no. of trees.
Step-4: For new data points, find the predictions of each decision tree, and assign the new data points to the category that wins the majority votes.
8. Building a Random Forest
To understand all these steps, consider the below sample data set. In this data set, we have four predictor variables, namely:
- Chest Pain
- Blood flow
- Blocked Arteries
- Weight

These variables are used to predict whether or not a person has heart disease. We’re going to use this data set to create a Random Forest that predicts if a person has heart disease or not.
Creating a Bootstrapped Dataset from Original Dataset
Bootstrapping is an estimation method used to make predictions on a data set by re-sampling it. To create a bootstrapped data set, we must randomly select samples from the original data set. A point to note here is that we can select the same sample more than once.

I have randomly selected samples from the original data set in the above table and created a bootstrapped data set. Simple, isn’t it? Well, in real-world problems, you’ll never get such a small data set. Thus creating a bootstrapped data set is a little more complex.
Creating Decision Trees
- Our next task is to build a Decision Tree using the bootstrapped data set created in the previous step. Since we’re making a Random Forest, we will not consider the entire data set that we created. Instead, we’ll only use a random subset of variables at each step.
- Ensemble models, like Random Forest, work best if the individual models (individual trees in our case) are uncorrelated. In Random Forest, this is achieved by randomly selecting certain features to evaluate at each node. m = p Where m is the no. of features used at each node and p is the total no. of features. In this example, we’re only going to consider 2 ( = 4 ) variables at each step. So, we begin at the root node, here we randomly select two variables as candidates for the root node.
- Let’s say we selected Blood Flow and Blocked arteries. Out of these 2 variables, we must now select the variable that best separates the samples. For the sake of this example, let’s say that Blocked Arteries is a more significant predictor and thus assign it as the root node.
- Our next step is to repeat the same process for each of the upcoming branch nodes. Here, we again select two variables at random as candidates for the branch node and then choose a variable that best separates the samples.
Just like this, we build the tree by only considering random subsets of variables at each step. By following the above process, our tree would look something like this:

We just created our first Decision tree.
Go back to Step 1 and Repeat N number of times to build N trees
Like I mentioned earlier, Random Forest is a collection of Decision Trees. Each Decision Tree predicts the output class based on the respective predictor variables used in that tree. Finally, the outcome of all the Decision Trees in a Random Forest is recorded, and the class with the majority votes is computed as the output class.
Thus, we must now create more decision trees by considering a subset of random predictor variables at each step. To do this, go back to step 1, create a new bootstrapped data set and then build a Decision Tree by considering only a subset of variables at each step. So, by following the above steps, our Random Forest would look something like this:
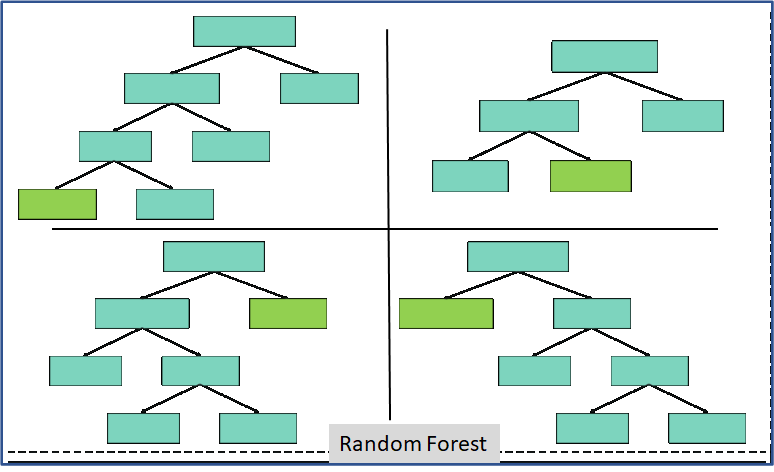
This iteration is performed 100’s of times, creating multiple decision trees with each tree computing the output using a subset of randomly selected variables at each step.
Having such a variety of Decision Trees in a Random Forest makes it more effective than an individual Decision Tree created using all the features and the whole data set.

Similarly, we run this data down the other decision trees and keep track of the class predicted by each tree. After running the data down all the trees in the Random Forest, we check which class got the majority votes. In our case, the class ‘Yes’ received the most number of votes. Hence it’s clear that the new patient has heart disease.
9. Advantages and Challenges of Random Forest
There are several key advantages and challenges that the random forest algorithm presents for classification or regression problems. Some of them include:
Advantages:
- Reduced risk of overfitting: Decision trees run the risk of overfitting as they tend to fit all the samples within training data tightly. However, when there’s a robust number of decision trees in a random forest, the classifier won’t overfit the model since the averaging of uncorrelated trees lowers the overall variance and prediction error.
- Provides flexibility: Since random forest can handle both regression and classification tasks with a high degree of accuracy, it is a popular method among data scientists. Feature bagging also makes the random forest classifier an effective tool for estimating missing values as it maintains accuracy when a portion of the data is missing.
- Easy to determine feature importance: Random forest makes it easy to evaluate variable importance, or contribution, to the model. There are a few ways to assess feature importance. Gini importance and mean decrease in impurity (MDI) are usually used to measure how much the model’s accuracy decreases when a given variable is excluded. However, permutation importance, also known as mean decrease accuracy (MDA), is another important measure.
Other Advantages as listed in the original paper about Random Forest(Breiman, 2001)
- Accuracy is as good as Adaboost and sometimes better.
- It is faster than bagging or boosting.
- It gives useful internal estimates of error, strength, correlation and variable importance.
- It is simple and easily parallelized.
Challenges:
- Time-consuming process: Since random forest algorithms can handle large data sets, they can provide more accurate predictions and be slow to process data as they are computing data for each decision tree.
- Requires more resources: Since random forests process larger data sets, they’ll need more resources to store that data.
More complex: The prediction of a single decision tree is easier to interpret when compared to a forest of them.
10. Practical Applications
There are several applications where a Random Forest analysis can be applied. We will discuss some of the sectors where random forest can be used. We will also look closer when the random forest analysis comes into the role.
Banking Sector: The banking sector consists of most users. There are many loyal customers and also fraud customers. Random Forests can be used to determine whether a customer is loyal or fraudulent. With the help of a random forest algorithm in machine learning, we can quickly determine whether the customer is fraud or loyal. A system uses a random algorithm that identifies the fraud transactions by a series of the pattern.
Medicines: Medicines needs a complex combination of specific chemicals. Thus, to identify the great combination in the medication, Random forest can be used. With the help of machine learning algorithm, it has become easier to detect and predict the drug sensitivity of a medicine. Also, it helps to identify the patient’s disease by analyzing the patient’s medical record.
Stock Market: Machine learning also plays a role in stock market analysis. When you want to know the behaviour of the stock market, with the help of the Random Forest algorithm, the behaviour of the stock market can be analyzed. Also, it can show the expected loss or profit which can be produced while purchasing a particular stock.
E-Commerce: When you find it difficult to recommend or suggest what type of products your customer should see. This is where you can use a random forest algorithm. Using a machine learning system, you can recommend the products which will be more likely for a customer. Using a specific pattern and following the product’s interest of a customer, you can suggest similar products to your customers.




