
Introduction:-
In this post , we’ll talk about Focal loss for object detection !!
With advancement in technology, object detection is one of the most widely studied topic in computer vision community. It’s has been breaking into various industries with use cases from image security, surveillance, automated vehicle systems to machine inspection.
Currently, deep learning based object detection can be majorly classified into two groups: –
- Two-stage detectors, such as Region-based CNN (R-CNN) and its successors.
- And, One-stage detectors, such as the YOLO family of detectors and SSD
One-stage detectors that are applied over a regular, dense sampling of anchor boxes (possible object locations) have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors because of extreme class imbalance encountered during training.
FAIR has released paper in 2018, in which they introduced the concept of Focal loss to handle this class imbalance problem with their one stage detector called RetinaNet.
Table of Contents: –
- Why Focal Loss Needed
- What is Focal Loss
- Cross Entropy Loss
- Problem with Cross Entropy
- Examples
- Balanced Cross Entropy
- Problem with Balanced Cross Entropy
- Examples
- Focal loss explanation
- Examples
- Cross Entropy vs Focal Loss
- Easily correctly classified records
- Misclassified records
- Very easily classified records
- Final Thoughts
Why Focal Loss Needed? :–
What is class imbalance problem? –
Both classic one stage detection methods, like boosted detectors, DPM & more recent methods like SSD evaluate almost { 10 }^{ 4 }to { 10 }^{ 5 }candidate locations per image but only a few locations contain objects (i.e. Foreground) and rest are just background objects. This leads to class imbalance problem.
This imbalance causes two problems –
- Training is inefficient as most locations are easy negatives (meaning that they can be easily classified by the detector as background) that contribute no useful learning.
- Since easy negatives (detections with high probabilities) account for a large portion of inputs. Although they result in small loss values individually but collectively, they can overwhelm the loss & computed gradients and can lead to degenerated models.
What is Focal Loss: –
In simple words, Focal Loss (FL) is an improved version of Cross-Entropy Loss (CE) that tries to handle the class imbalance problem by assigning more weights to hard or easily misclassified examples (i.e. background with noisy texture or partial object or the object of our interest) and to down-weight easy examples (i.e. background objects).

So Focal Loss reduces the loss contribution from easy examples and increases the importance of correcting misclassified examples.)
So, let’s first understand what Cross entropy loss for binary classification-
Cross Entropy Loss: –
The idea behind Cross Entropy loss is to penalize the wrong predictions more than to reward the right predictions. Cross entropy loss for binary classification is written as follows-

Where-
{ Y }_{ act }=Actual Value of Y
{ Y }_{ pred}=Predicted Value of Y
For Notational convenience, let’s write { Y }_{ pred } as p & { Y }_{ act } as Y.
Where-
Y∈{0,1}, It’s the ground truth class
p∈[0,1], is the model’s predicted probability for the class with Y=1.
For notation convenience, we can rewrite above equation as –

\displaystyle CE(p,y)=CE({{p}_{t}})=-\ln ({{p}_{t}})
Problem with Cross Entropy: –
As you can see, blue line in below diagram, when p is very close to 0 (when Y=0) or 1, easily classified examples with large { p }_{ t } >>0.5 can incur a loss with non-trivial magnitude.

Let’s understand it using an example below-
Examples: –
Let’s say, Foreground (Let’s call it class 1) is correctly classified with p=0.95 –
CE(FG) = -ln (0.95) =0.05
And background (Let’s call it class 0) is correctly classified with p=0.05 –
CE(BG)=-ln (1- 0.05) =0.05
The problem is, with class imbalanced dataset, when these small losses are sum over the entire images can overwhelm the overall loss (total loss). And thus, it leads to degenerated models.
Balanced Cross Entropy Loss: –
A common approach to address such class imbalance problem is to introduce a weighting factor \alpha \epsilon [0,1] for class 1 & 1-\alpha for class 0 or negative class.
For notational convenience, we can define { \alpha }_{ t } in loss function as follows-
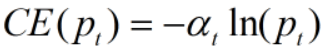
As you can see, this is just an extension to Cross Entropy.
Problem with Balanced Cross Entropy: –
As our experiments will show, the large class imbalance encountered during training of dense detectors overwhelms the cross-entropy loss.
Easily classified negatives comprise the majority of the loss and dominate the gradient. While balances the importance of positive/negative examples, it does not differentiate between easy/hard examples. Let’s understand this with an example-
Examples: –
Let’s say, Foreground (Let’s call it class 1) is correctly classified with p=0.95 –
CE(FG) = -0.25*ln (0.95) =0.0128
And background (Let’s call it class 0) correctly classified with p=0.05 –
CE(BG)=-(1-0.25) * ln (1- 0.05) =0.038
While it does good job differentiating positive & negative classes correctly but still does not differentiate between easy/hard examples. And that’s where Focal loss (extension to cross entropy) comes to rescue.
Focal loss explanation: –
Focal loss is just an extension of cross entropy loss function that would down-weight easy examples and focus training on hard negatives. So to achieve this researchers have proposed { (1-{ p }_{ t }) }^{ \gamma } to the cross entropy loss ,with a tunable focusing parameter γ≥0.
RetinaNet object detection method uses an α-balanced variant of the focal loss, where α=0.25, γ=2 works the best.
So focal loss can be defined as –

The focal loss is visualized for several values of γ ∈[0,5] , refer Figure 1.
We shall note following properties of the focal loss-
- When an example is misclassified and { p }_{ t } is small, the modulating factor is near 1 and the loss is unaffected.
- As , { p }_{ t }\rightarrow 1 , the factor goes to 0 and the loss for well classified examples is down weighed .
- The focusing parameter γ smoothly adjusts the rate at which easy examples are down-weighted.
- As , γ is increased , the effect of modulating factor is likewise increased. ( After a lot of experiments and trials , researchers have found γ=2 to work best)
Note: – When γ=0 , FL is equivalent to CE (Shown blue curve in Figure 1)
Intuitively, the modulating factor reduces the loss contribution from easy examples and extends the range in which an example receives the low loss.
Let’s understand the above properties of focal loss using an example-
Examples: –
When record (either foreground or background) is correctly classified \Longrightarrow
Foreground is correctly classified with predicted probability p=0.99 and background is correctly classified with predicted probability p=0.01.

Modulating factor (FG)= { (1-0.99) }^{ 2 }=0.0001
Modulating factor (FG)= { (1-(1-0.01)) }^{ 2 }=0.0001
As you can see, modulating factor is close to 0, in turn loss would be down- weighted.
When record (either foreground or background) is misclassified \Longrightarrow
Foreground is mis-classified with predicted probability p=0.01 for background object misclassified with predicted probability p=0.99.

Modulating factor (FG)= { (1-0.01) }^{ 2 }=0.9801
Modulating factor (FG)= { (1-(1-0.99)) }^{ 2 }=0.9801
As you can see, modulating factor is close to 1, in turn loss is unaffected. Now let’s compare Cross Entropy and Focal loss using few examples and see the impact of focal loss in training process.
Cross Entropy vs Focal Loss: –
Let’s see the comparison by considering few scenarios below-
Easily correctly classified records\Longrightarrow
Let’s say Foreground is correctly classified with predicted probability p=0.95 and background is correctly classified with predicted probability p=0.05.

CE(FG)= -ln (0.95) = 0.051
CE(BG)= -ln (1-0.05) = 0.051
Let’s consider the same scenario Focal loss with ∝=0.25 & γ=2.
FL(FG)= -0.25{ (1-0.25) }^{ 2 }ln (0.95) = 3.20\times { 10 }^{ -5 }
FL(BG)= -0.75{ (1-(1-0.05)) }^{ 2 }ln (1-0.05) = 9.61\times { 10 }^{ -5 }
Misclassified records\Longrightarrow
Let’s say foreground is classified with predicted probability p=0.05 for background object misclassified with predicted probability p=0.95.

CE(FG)= -ln (0.05) = 2.995
CE(BG)= -ln (1-0.95) = 2.995
Let’s consider the same scenario Focal loss with ∝=0.25 & γ=2.
FL(FG)= -0.25{ (1-0.05) }^{ 2 }ln (0.05) = 0.67
FL(BG)= -0.75{ (1-(1-0.95)) }^{ 2 }ln (1-0.95) = 2.027
Very easily classified records\Longrightarrow
Let’s say foreground is classified with predicted probability p=0.99 for background object misclassified with predicted probability p=0.01.

CE(FG)= -ln (0.99) = 0.01005
CE(BG)= -ln (1-0.01) = 0.010050
FL(FG)= -0.25{ (1-0.01) }^{ 2 }ln (0.99) = 2.51\times { 10 }^{ -7 }
FL(BG)= -0.75{ (1-(1-0.01)) }^{ 2 }ln (1-0.01) = 7.53\times { 10 }^{ -7 }
Final Thoughts: –
Scenario-1: 0.05129/3.20\times { 10 }^{ -5 }= 1600 times smaller number
Scenario-2: 2.3/0.667 = 4.5 times smaller number
Scenario-3: 0.01/2.51\times { 10 }^{ -5 } = 40,000 times smaller number.
These three cases clearly explain that how Focal loss adds down weights the well classified records and on the other hand assigns large weight to misclassified or hard classified records.
After a lot of trials and experiments, researchers have found ∝=0.25 & γ=2 to work best.
In next article we’ll talk about RetinaNet model for object detection in detail.
End Points: –
We went through the complete journey of evolution of cross entropy loss to focal loss in object detection. I’ve tried my bit to explain focal loss in object detection as simple as possible. Please feel free to comment down your queries. I’ll be more than happy to answer them.
If you’ve enjoyed this article, leave a few claps, it will encourage me to explore more machine learning techniques & pen them down 🙂
Happy learning. Cheers!!
Don’t forget to checkout below articles-




